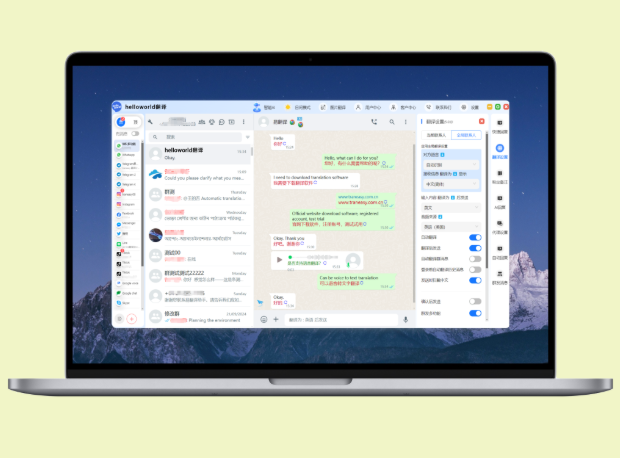
HelloWorld的批量翻译功能一般支持同时向多个目标语言输出,但能同时翻译多少种语言、是否并行处理、翻译质量与输出格式,会受软件版本、硬件性能、网络状况和订阅权限等多项因素影响。我接下来会分步骤说明原理、限制与实操建议,帮助你判断并高效使用。同时给出操作示例与常见问题的应对策略。可立即试用。再看。

先把问题拆成三小块:能不能、怎么做、注意什么
用费曼法讲就是:先把概念讲清楚,再把流程讲清楚,最后把常见坑说清楚。简单来说,批量翻译就是把多条文本或一个文件集合一次性投入系统,让系统按规则输出多种语言的译文。关键点在“多种语言”与“批量”这两个维度上,它们既相关也独立。
什么是“同时翻多个语言”
- 并行输出:同一输入在同一时间点被翻成多种目标语言(比如一段英文同时得到法语、日语、西班牙语的译文)。
- 批量处理:一次性提交很多条或很多文件,系统按队列批量处理并返回结果。
- 并行与批量可以同时存在:你可以批量提交多条记录,同时每条记录又可以被翻译成多种语言。
HelloWorld(LookWorldPro 类产品)通常的实现方式
从工程角度看,这类工具有两种常见架构:
- 本地客户端+云服务模式:前端APP或网页版上传任务,云端翻译引擎负责并行计算,结果返回;本地用于排队、展示、简单校验。
- 服务器本地部署模式:企业用户在自有服务器或边缘设备上运行模型,数据不出站,适合高安全需求场景。
并行度从哪儿来?(核心机制)
并行度由三部分决定:软件的任务调度能力、后端翻译模型的并行处理能力(是否支持同时多语言推理)、以及你的资源配额(CPU/GPU、带宽、API并发限制)。换句话说,产品可以做这件事,但能做多少、做多快,取决于后台和你的账户级别。
实操:你想要的五种使用场景与步骤
下面按场景讲清楚该怎么操作,像在厨房里一步步做菜一样。
场景一:社媒帖子同时发布多语版(短文本,高频)
- 步骤:准备好一列原文 → 选择目标语言(比如 10 种)→ 选择“批量翻译”为每条并行输出多语 → 快速审核 → 导出或直接发布。
- 建议:选择云端并发服务或高级套餐,保证延迟低。短句通常准确率高。
场景二:产品列表(电商)批量翻译到数十种语言
- 步骤:CSV/Excel 上传 → 对列映射(标题、描述、规格)→ 选择需要的目标语言组合 → 启动批处理 → 下载多语CSV或每语种分文件。
- 建议:先抽样校验 5–10 条,建立术语表或用术语强制替换,保持品牌词一致。
场景三:长文档或学术论文(大段落,讲求准确)
- 建议:分片提交(按章/段),并行度适中,结合人工校审;对于特定术语,预先上传术语表或参考译文。
场景四:语音或图片批量翻译(多模态)
- 流程:先做语音识别或 OCR → 得到文本批量处理 → 输出多语。并行点在文本阶段,识别阶段通常是先后顺序但可以并发多个文件。
场景五:实时会话与多语言字幕(极低延迟需求)
- 这类需要流式并行翻译,系统会把源流同时转发到多个目标语言通道,考验的是实时编排与带宽。
性能、成本与限制的具体要素
不要只问“能不能”,还得问“用多少时间和钱”。下面是影响并行批量翻译的关键因素:
- 账号等级/订阅:免费或低级账号通常有限并发和每日额度,高级企业账号可以开更高并发。
- 后端模型能力:有的引擎支持多目标同时推理(一次性生成多语句),更高效;有的需要为每个目标单独调用模型。
- 资源(硬件/带宽):GPU/多核CPU 能显著提速,网络延迟会影响总体完成时间。
- 格式与大小:大文件(视频、整本书)要分片;复杂格式(表格、保留标签)需要额外处理。
- 质量控制:机器译文需要后编辑(PE)或术语一致性工具来保证专业领域准确。
一个表格比较不同批量模式(便于快速判断)
| 模式 | 并行能力 | 适用场景 | 优点 | 缺点 |
| 普通云API(逐语种调用) | 中等(受API并发限制) | 小批量、多语种但不超高并发 | 易用、成本可控 | 效率低于多语并行引擎 |
| 多语并行引擎(一次生成多语) | 高 | 社媒、营销内容、短文本批量 | 速度快、并发高 | 对专有术语支持需额外配置 |
| 本地部署(企业版) | 取决于自有资源 | 数据敏感/合规场景 | 数据可控、吞吐可调 | 初期投入大、维护成本高 |
实用技巧和容易被忽略的细节
- 先抽样再批量:不要直接全量跑,先拿 1%–5% 数据走完整流程。
- 构建术语表:把品牌名、专业词加入强制替换表,避免被误翻。
- 格式保留:表格、HTML 标签或占位符要用占位策略,防止译文打乱结构。
- 并发安全:当用 API 并发请求时注意速率限制,超限会被限流或计费异常。
- 分批策略:把任务按大小和紧急度分批提交,更好利用资源。
常见问题(FAQ)
1. 能同时翻 200 种语言吗?
理论上很多平台支持 200+ 语言集合,但能否“一次性并行生成 200 个译文”还要看引擎和配额。很多情况下系统会把目标语言拆成多个子任务并排队执行。
2. 如果我提交一个 Excel,结果会按语言分文件吗?
多数产品支持按语种导出单独文件或在原表中增加多列,每种实现不同,可以在导出设置选择。
3. 翻译质量能保证吗?
机器翻译在日常用语和常见短文本上表现好;在法律、医疗、专利等领域需要人工后编辑。使用术语表和自定义模型可以明显提升一致性。
小结与马上动手的建议(边想边写)
如果你现在想试,建议这样做:1)确定目标语种清单;2)选取 50 条代表性样本;3)用 HelloWorld 的批量接口或界面同时请求这些语种;4)检查时间、并发错误与译文质量;5)根据结果调整并发、分片和术语表。这个流程听起来有点啰嗦,但能省掉后面很多返工时间。
写到这里,我又想到一个事儿:如果你关心的是成本,可先对比按字符计费与按请求计费的差别,短句高频场景按请求计费有时候更省;长文按字符计费会更划算。好,就到这里,反正操作起来能立刻看到效果,边试边改吧。