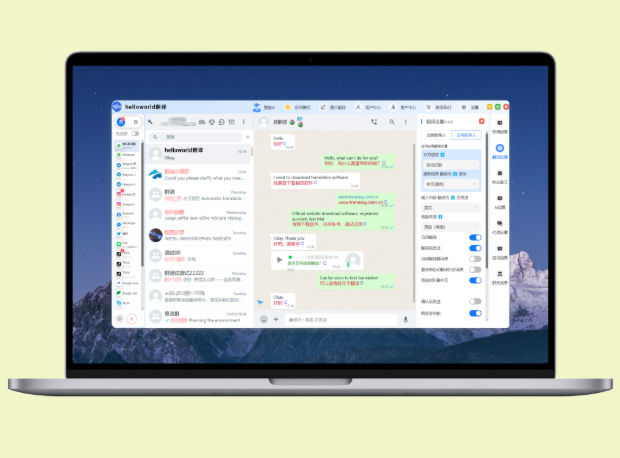
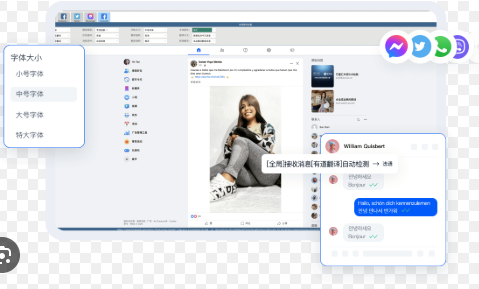
HelloWorld 是一款多模态智能翻译工具,支持超过200种语言互译,包含英语、日语、韩语在内的主流语种都能处理,并提供文本、语音和图片识别等输入方式;在日常交流、旅游场景、跨境电商与技术文档处理中,可以通过模型选择、术语表和上下文提示来提高精准度,同时兼顾在线与离线、隐私保护与多平台整合能力。

先把问题拆开:它能翻译英语、日语、韩语吗?
答案是肯定的,但“能翻译”并不等同于“在任何情况下都完美无误”。把这件事像搭积木一样看:第一块是“语言覆盖”,第二块是“输入形式”(文本、语音、图片),第三块是“场景与质量要求”(口语、专业术语、长文档)。HelloWorld 在第一块上有坚实基础,在第二、第三块可以通过配置和人工后处理进一步提升结果。
功能维度的拆解(为什么能)
1. 语言覆盖
- 英语:作为全球通用语,模型训练数据丰富,常规文本和日常会话的准确率通常很高。
- 日语:支持假名、汉字混写(和式表达)、敬语判断与语境区分,需要分词和断句处理,HelloWorld 提供了针对日语的专门处理流程。
- 韩语:支持韩文(한글)、罗马化与语法结构处理,注重语尾敬语体系与词序转换。
2. 输入方式
- 文本翻译:单句/段落/整篇文档,多数场景下表现稳定。
- 语音翻译:语音识别 + 机翻合成;对话场景可以做到实时,但口音、噪声会影响识别率。
- 图片(OCR)翻译:对印刷体效果好,对手写、竖排(常见于日语)或复杂背景会受限,需要适当的图像预处理。
对英语、日语、韩语的具体表现与注意点
英语
英语的挑战更多在风格和语域:比如商务邮件要正式、社交聊天可以口语化。HelloWorld 通常能区分常见语域,但如果你需要行业术语或特定风格(法律、医学、IT 文档),建议加载相应术语表或选择专业模型。
日语
日语特有的问题包括:省略主语、敬语层级、汉字与假名混写、没有空格的断句。举个简单例子,短句“お願いします”在不同语境下可以翻译为“Please”、“I would appreciate it”或“Please take care of this”,系统需要上下文来判断。HelloWorld 在日语处理上通常会做一步额外的语境推断和敬语识别,但面对长篇文学或带地方方言的口语,仍然建议人工校对。
韩语
韩语的挑战在于词尾变化、敬语和连词结构。与中文或英语比较,韩语句子通常以动词结尾,翻成英文或中文时需要调整词序。HelloWorld 的韩语模块能处理大多数标准用法,若遇到缩略语、俚语或行业术语,也建议补入词表或人工后编辑。
如何在实际使用中把准确率最大化(像教朋友一样说明)
把翻译质量比作烹饪:好食材(上下文和术语表)+ 好厨具(专业模型)+ 好厨师(后期人工审校),才做出好菜。下面是具体步骤。
实用步骤
- 提供足够上下文:不要只丢一两个词,整句或整段更容易得到准确翻译。
- 选择场景/领域:如果 HelloWorld 提供“法律/医疗/电商”选项,选择相应领域模型。
- 建立术语表(glossary):对专有名词、品牌名、技术术语指定固定译法,避免被模型随意变换。
- 利用句子示例(prompt):给出一两个参考翻译,让系统学习你的偏好(口语/书面/简洁/详细)。
- 人工后编辑:对于合同、投标书、产品说明书等高风险文本,建议人工校对或双语审核。
速度、离线与隐私
很多人关心的两个问题:速度与数据安全。HelloWorld 通常有在线云端翻译(模型大、更新快、适合高精度任务)和离线本地模型(隐私好、响应快、但占空间且模型体量受限)。如果你在机密项目上工作,优先考虑本地离线模式或企业托管方案。
| 特性 | 在线云端 | 离线本地 |
| 模型大小与最新性 | 大、更新快 | 小、更新慢 |
| 隐私 | 视服务条款,通常有加密 | 高(数据不出设备) |
| 适合场景 | 高精度/大批量翻译 | 离线、受限网络或敏感数据 |
典型场景举例(一步步演示)
场景一:旅行时的即时口语翻译
你对着手机说日语短句,HelloWorld 先做语音识别,再机翻成中文或英语,然后语音合成回放。注意:嘈杂环境、方言或快速语速会降低识别率。小技巧是把句子说慢一点,并补充背景(“在餐厅,我要点菜”)。
场景二:电商商品页从日语/韩语翻译到中文
商品标题和属性要精准,建议先导入术语表(品牌名、型号、尺寸等),再做批量翻译,最后由人工审校商品描述以避免影响销量。
场景三:技术文档或学术论文
选择专业模式、上传参考文献、导入专有术语表,翻译后请专门人员进行校对,因为自动翻译在长句结构、公式说明或引用处理上容易出偏差。
常见问题与排错建议(像和朋友聊天)
- 翻译显得生硬或过于字面? 试着提供更多上下文,或选“更自然”风格选项。
- OCR 无法识别竖排日文或模糊图片? 先用图像编辑提高对比度,或手动拍扁图片(避免角度倾斜),再尝试识别。
- 专业术语被误翻? 建立并上传术语表,或在文本中注释结合原文。
- 语音识别错误率高? 检查是否选择了正确语种,减少背景噪声并使用接近麦克风的录音。
评估翻译质量:你可以怎么检验
常见的自动化指标有 BLEU、ROUGE、TER 等,但这些指标对单句、语感与礼貌性判断有限。最可靠的是人工评估:让目标受众或双语专家查看翻译是否“在语境下自然且无歧义”。
和常见竞争产品的比较(一句话说明)
像 Google Translate、DeepL 等工具也支持英语、日语、韩语;HelloWorld 的特点在于多平台整合、可配置的术语管理与企业级隐私选项,具体优劣取决于你的使用场景和对行业适配的需求。
开发者与企业集成注意点
- 查阅 HelloWorld 的 API 文档,确认支持的端点(文本翻译、语音识别、OCR 等)。
- 测试延迟与并发性能,确保满足业务峰值。
- 设置合理的缓存与批量处理策略,降低成本与响应时间。
- 遵守数据合规(比如隐私条款、GDPR 等适用范围),必要时使用企业托管或本地部署。
一个稍微技术点的说明(为什么机器翻译有时会出错)
简单说,机器翻译靠概率和模式匹配来“猜”最可能的翻译。对于英语-日语-韩语这种跨语系翻译,结构差异(词序、敬语、主语省略)让模型需要更多上下文与领域约束。就像你把中文诗直接翻成英文,保留韵律与意境并不容易,机器也一样,需要人的介入来把“意图”处理好。
最后,给你几条实用小贴士(快速参考)
- 短句优先:短句更容易准确翻译,复杂句子可分句处理。
- 术语表不可少:特别是品牌名、型号、技术词汇。
- 结合音频与文本:语音先转文本再翻译,必要时人工校听。
- 对高风险文档做双语审校:合同、法律、医学类文件一定要人审。
写着写着,我意识到每个人的需求其实不太一样——有的人只要聊天能通,有的人要逐字精准,还有人关心隐私和成本。HelloWorld 在基础能力上是覆盖英语、日语、韩语的,但具体“好不好用”,还是要看你怎么配置、怎么使用以及是否加入人工校对。你可以先从小批量免费试用开始,把常见短语和术语表先准备好,再逐步扩展到更多场景,这样会更省心也更靠谱。