HelloWorld 电脑版上,翻译结果可以通过多种方式分享:直接复制粘贴、使用界面上的“分享/导出”按钮导出为文本、PDF、图片或字幕文件、生成云端链接供他人访问,或直接发送到第三方应用(如微信、邮件、Slack 等)。一般流程是选中翻译结果→点击分享图标→选择目标格式或应用→确认并可设置隐私与格式选项。不同场景下选择不同方式可以兼顾格式保留、可编辑性和隐私安全。

为什么要了解这些分享方式(用最简单的话说)
把翻译结果分享出去,其实和把一张纸条交给别人差不多:你可以直接把纸条递过去(复制粘贴)、把纸条放进信封邮寄(导出成文件)、拍张照发给对方(截图或图片导出),或把纸条放在桌面上给大家拿(云端链接)。不同传递方式对便捷性、完整性、隐私性有不同影响,理解这些差别才能在工作或旅行中少走弯路。
概览:HelloWorld 电脑版常见的分享方式
- 复制粘贴:最直接、最快,但不保留格式或元数据。
- 内置“分享/导出”功能:支持导出为文本、PDF、图片、SRT/字幕等格式,适合保留格式或批量导出。
- 生成云端链接:方便多人访问或长时间共享,支持权限管理。
- 第三方应用直发:直接发送到微信、邮件、Slack 等,适合即时沟通。
- 剪贴板历史与批量导出:适合多条翻译结果的管理与回溯。
什么时候用哪种方式(实用场景)
- 临时回复朋友:复制粘贴或直接分享到微信。
- 向客户提交正式文档:导出为PDF或DOCX,保留排版和页眉页脚。
- 制作字幕或视频配音稿:导出为.srt/.vtt 格式。
- 多人协同校对:生成云端链接并设置只读/可编辑权限。
- 保存记录备查:使用本地文件保存或导出到笔记服务。
详细操作步骤(一步步来)
下面按功能把具体步骤拆开,跟着做就能跑通。界面名称可能会随着版本略有差异,但基本逻辑一致:选中→分享→选择方式→确认。
一、复制粘贴(最快的方法)
- 用鼠标或键盘快捷键(Ctrl/Cmd + A/C)选中翻译结果。
- 按 Ctrl/Cmd + C 复制,然后在聊天、文档或邮箱中粘贴(Ctrl/Cmd + V)。
- 注意:复制不会保留特殊格式(如表格、注释),也不会带图片或语音文件。
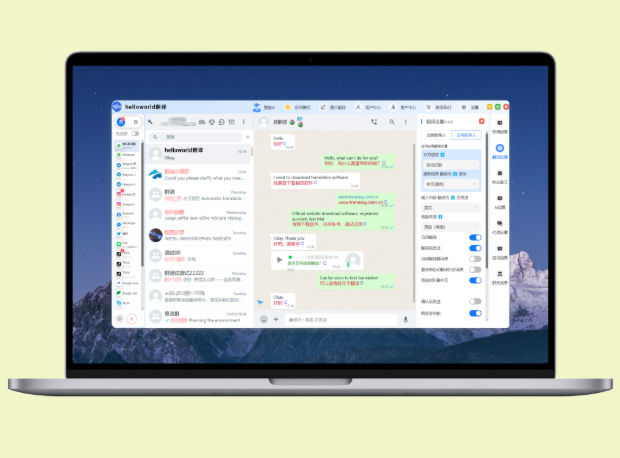
二、内置“分享/导出”按钮(最常用、功能最全)
通常位于翻译结果窗格右上角,图标可能是一个分享箭头或“导出”字样。
- 点击“分享/导出”。
- 选择导出格式:
- 纯文本(.txt / .md):适合编辑或粘贴到代码/笔记里。
- 文档(.docx / .pdf):保留排版,用于正式提交或打印。
- 图片(.png / .jpg):保留视觉效果,用于社交媒体或聊天截图替代。
- 字幕文件(.srt / .vtt):用于视频字幕同步。
- 压缩包(.zip):批量导出多条翻译时会打包。
- 设置选项(如保留原文、包含时间戳、是否脱敏等)。
- 选择保存位置或直接发送到目标应用。
三、生成云端共享链接(多人协作或长链分享)
- 点击“分享/导出”→选择“生成链接”或“上传并分享”。
- 选择访问权限:公开、仅有链接可访问、或特定用户可访问。
- 可设置有效期或密码保护(注:这些选项取决于账户等级和隐私政策)。
- 复制链接后,可粘贴到聊天、邮件或团队协作工具。
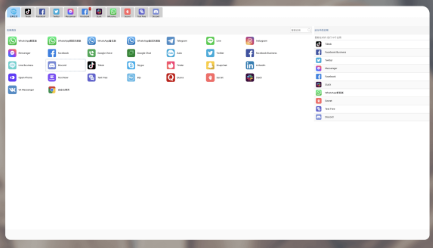
四、直接发送到第三方应用(快捷分享)
某些版本支持一键发送到本机安装的应用或集成的云服务。
- 点击“分享”→选择目标应用(例如:微信桌面、Outlook、Slack)。
- 如果是发送到微信,软件可能会调用微信桌面窗口,确认后消息会发出;邮件会打开新建邮件窗口并自动填入内容或附件。
- 注意:桌面分享依赖本机应用支持和权限。
五、截图或导出为图片(当格式很重要时)
- 在分享菜单中选择“导出为图片”,或使用操作系统截图工具截取翻译区域。
- 图片方便在社交媒体或不想被编辑的场景下使用,但不可轻易复制文本(需要 OCR 才能提取)。
对比表:主要分享方式一目了然
| 方式 | 适合场景 | 优点 | 缺点 |
| 复制粘贴 | 即时聊天、临时回复 | 快速、无需设置 | 无法保留复杂格式、隐私风险 |
| 导出为PDF/DOCX | 正式文档提交、打印 | 保留排版、便于归档 | 体积较大,修改不便 |
| 生成云端链接 | 协作校对、长期共享 | 可控制权限、实时更新 | 依赖网络和服务稳定性 |
| 发送到第三方应用 | 即时沟通、团队协作 | 快捷、一体化流程 | 受限于本机应用与权限 |
隐私与安全:分享时别忽视的细节
- 敏感信息脱敏:在导出或分享前,特别是PDF或云链接,先检查是否包含邮箱、身份证号、地址等敏感内容。
- 权限设置:生成链接时优先选择“仅有链接可访问”并加密码,避免公开索引。
- 保存位置:本地保存建议放在受保护的文件夹或加密盘,云端保存要确认服务商的隐私条款。
- 审计日志:如果是企业账户,查看谁在何时访问过共享内容很重要,HelloWorld 的企业版通常支持审计功能。
常见问题与解决办法(你可能会遇到的那些小坑)
1. 分享后对方看不到格式或乱码
通常是因为目标应用不支持源文件编码或特殊字符。解决方法:导出为 PDF(保留排版)或在导出选项中选择 UTF-8 编码。
2. 云端链接提示权限不足
检查是否设置了“仅限内部用户”或链接已过期。再次生成链接并确认访问权限,或直接发送给指定邮箱。
3. 直接发送到微信失败
很多时候是因为微信桌面未登录或未授权 HelloWorld 访问。确认微信已登录并在系统隐私设置中允许应用间互通。
4. 导出字幕时间轴不同步
导出前确认源音频的时间点是否已正确检测;必要时手动校准时间码,或导出为可编辑的 .srt 再用字幕工具微调。
进阶技巧(让分享更顺手)
- 把常用导出格式设为默认,这样一键就能把内容保存为你需要的样式。
- 使用模板功能:若你经常向客户发送带公司签名的翻译报告,可建立导出模板自动加入页眉页脚。
- 批量处理:当有大量句段需要分享时,先用批量导出生成 zip,再统一发送,省时省力。
- 结合快捷键:熟悉复制、粘贴、快速导出(若支持)等快捷键,能在会话中表现得更专业。
举个真实小例子,说明怎么操作(带点生活气息)
上周我需要把一段产品说明从英文翻到中文,发给海外供应商确认。流程是:把整段文本粘进 HelloWorld → 选中翻译结果 → 点击“导出”→ 选择“PDF(包含原文)”并勾选“保留段落编号”→ 生成后直接在邮件客户端打开并作为附件发送。供应商回复说格式不错,不用再调整,节省了好几轮邮件往返。嗯,就像把一封排好字的信直接交到对方手里。
如果你还是不确定,用这个快速检查表
- 我需要保留排版吗?是→导出为 PDF / DOCX。
- 对方需要可编辑文件吗?是→导出为文本或 DOCX。
- 需要多人长期查看或编辑吗?是→生成云端链接并设置权限。
- 只是临时回复消息?是→复制粘贴或发送到聊天工具。
好了,按这个思路去试一次就能掌握。每种方式背后的逻辑其实都挺简单:你要考虑的是“接收方如何使用”和“我需要保留哪些信息”,剩下的就是按按钮、选选项、发出去。如果遇到具体界面名称不一样,那就把关键词(分享、导出、链接、发送)在 HelloWorld 的菜单里找一遍,基本都能定位到;要是碰到权限或编码问题,通常调整导出选项或换成 PDF 就能解决。顺手使用几次,你会发现分享流程能像写聊天消息一样自然。